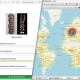
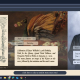
Newspaper Explorer
We developed a toolkit for exploring large datasets of digitized historical newspapers through computational analysis.
For our project we used the „Der Tag“ newspaper collection (1900–1920) from the Staatsbibliothek zu Berlin, containing ~135,000 ALTO XML files with 61+ million text lines from 135,000 page images, totaling over 10 GB of compressed XML and 200 GB of images.
Historical newspaper archives contain thousands of pages locked in ALTO XML format. Standard tools connecting raw data to modern NLP, computer vision, and LLM workflows are scarce. During the hackathon we struggled with processing data at this scale and had to refine our approaches when we continued working with the data: parallel parsing with Polars DataFrames, DuckDB for SQL queries on multi-GB datasets without loading into memory, and resume-capable pipelines that track processed files. Our project bridges this gap with a unified pipeline that downloads, parses, preprocesses, and analyzes newspaper data efficiently.
The toolkit combines diverse computational methods, e.g. GLiNER for named entity extraction, YOLOv11 for layout detection, emotion classification using a fine-tuned BERT model from Universität Würzburg, LLM-based topic modeling, and keyword extraction. A Vue/FastAPI web interface enables interactive exploration with entity timelines, image galleries, analysis visualizations, and full-text search. A CLI supports streamlined data processing.
Researchers can take a first step into unknown datasets, generating visualizations and insights that surface patterns and possibilities before specific research questions are formulated. A publication of the complete analysis results for the „Der Tag“ corpus on zenodo is planned after further optimization of the codebase.
All code for the project can be found on GitHub.



This project was created during the open cultural data hackathon