Uncertainties in the Archives
We explored uncertainties and ambiguities in geographical data provided by the Ethnological Museum in Berlin. Our data consists of semi-structured information about people and corporations connected to the museum until 1950.
After preprocessing using a simple Python script, we examined the data more closely and noticed that some places appear with many different spellings (e.g. Frankfurt) or include markers of uncertainty (e.g. question marks). Digging deeper revealed more complex challenges that we could not address automatically:
- Same name – different place: A single name refers to different geographical entities, e.g. Bali, which represents an island in Indonesia as well as a town and neighbourhood in modern Cameroon.
- Same place – different name: Different place names may refer to the same geographical entity due to varying spellings across languages (e.g. Wrocław and Breslau) or changes in name/attribution over time (Lahore (Pakistan) / Lahore (Indien) / Lahore (Britisch-Indien))
- Different levels of precision: Some names refer to cities, while others refer to broader regions or former colonies
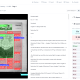
Using our expertise, we combined place names referring to the same location into a single entry within the available timeframe. To obtain corresponding geographical information in a computer-readable format, we used the GeoNames API and visualized all the data points we could find as a heatmap using QGIS.
We view the process of data preprocessing as a method to explore (cultural) data and gain initial insight into its structure and challenges.
All code for this project can be found on GitHub.
- `qa-live-event-guineapick.json`: data for the quizacademy quiz used during the hackathon (not available anymore)
- `EM_Entities.csv`: initial data provided by the Ethnological Museum Berlin via the Stabi Lab converted to CSV
- `EM_Entities_restructured.csv`: restructured version of the initial data where every type of location („Geo. Bez.“) is in its own column using `restructure_places.py`
- `EM_geonames.csv`: list of all available geographical entities mentioned in the data using `make_geonames_list.py`
- `EM_geonames_clean.csv`: manually cleaned data, different spellings of the same geographical location were copied into one line
- `EM_geonames_clean_coord-parts.csv`: data enriched with geo coordinates from GeoNames API where available
- `restructure_places.py`: adds a column for every type of location („Geo. Bez.“) in the data
- `make_geonames_list.py`: makes a list of all geo names in the data by using simple regex expressions
- `use_geonames_api_pandas.py`: reads the geonames list and makes a request to the GeoNames API. A own geonames account name is needed and API use is limited to 1000 requests/hour
This project was created during the open cultural data hackathon