
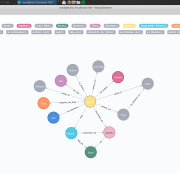
How can role models be represented? What relationships exist between specific role attributions, the activities performed and the source genres? Are there congruences between specific roles and source genres? These questions were answered by the team “Weibsbilder. World Wide Women” in the Hackathon Coding Gender. Based on the data sets Picturing Gender, Dolls Kitchens and […]

A proof of concept for Digital Humanities researchers – automatically enriched with metadata derived from various algorithms, including content-based image functions.
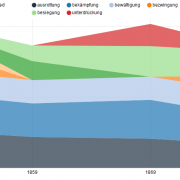
A visualization of concepts that change over time in digitized newspapers from the years 1882 to 1902 from the holdings of the Staatsbibliothek zu Berlin.

The bot “Berliner Schlagzeilen” twitters the headlines and a picture of the title page of the respective issue from 100 years ago on a daily basis.

The app Altpapier brings some of the most exciting and curious newspaper reports of the early 20th century to smartphones.